New Mining Techniques Effortlessly Provide Greater Insight for Unstructured Text Data
Aug 23, 2019 — Atlanta, GA
The ability to effectively and efficiently harness unstructured data has been the proverbial race to the moon for the data mining research world.
Unstructured data is information that is typically text-heavy and does not have a predefined model or is not organized in a predefined manner. It can represent the name of a disease, the location of a sale, a type of product sold, and much more. According to some estimates, it also accounts for roughly 85 percent of the data in the world.
However, acquiring useful insights from massive unstructured text data remains a challenge that was not readily addressed by existing mining techniques.
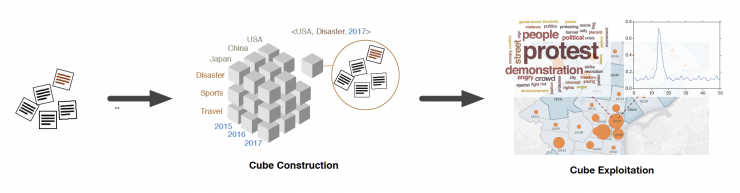
Now, a recently published Ph.D. defense combining two algorithms specializing in neural text classification and taxonomy construction, claims to do just that.
According to the defense, when these algorithms are used together, they create an elegant data mining pipeline that can effortlessly turn text data into useful insights. The algorithms allow for multi-dimensional analysis of unstructured text data using an integrated structuring-and-mining framework and discover multi-granular structures from the text.
School of Computational Science and Engineering Assistant Professor Chao Zhang developed the new techniques while studying under the direction of famed computer scientist Jiawei Han.The work has garnered so much recognition that it won the 2019 SIGKDD Runner Up Dissertation Award.
“As one of the most important data forms, unstructured text data plays a crucial role in data-driven decision making in domains ranging from social networking and information retrieval to healthcare and scientific research,” said Zhang.
“In many emerging applications, people's information needs from text data are becoming multi-dimensional – they demand useful insights for multiple aspects from the given body of a text.”
Zhang’s two-part pipeline addresses this multi-dimensional need while also tackling one of the biggest bottlenecks of mining unstructured text data: labeling. Labeled data represents a set of samples that have been tagged with one or more labels and is used in a form of machine learning called supervised learning.
Unfortunately, this is not always the practical approach for our world as data is often unlabeled and labeling a sufficient amount of data for training supervised models is often too expensive.
Therefore, an elegant data mining algorithm has to be able to discover latent structures from unstructured text data, or, be able to sort unstructured data into multiple categories without extensive labeling.This is where Zhang’s methods, which require no or very little labeling effort, truly shine.
“The algorithms for multidimensional text analysis require little supervision, making this framework appealing for many applications where labeled data are expensive to obtain,” he said.
Ultimately, while being more effective than other models, this proposed framework has two distinctive advantages: flexibility and label efficiency. Both of which, drive costs down dramatically.
Download the algorithms on GitHub here:
- Weakly-Supervised Neural Text Classification
- TaxoGen: Unsupervised Topic Taxonomy Construction by Adaptive Term Embedding and Clustering
Kristen Perez
Communications Officer



