Deep Learning Helps Robot Find Its Voice
Feb 26, 2019 — Atlanta, GA

Shimi and his team
Shimi the Robot’s Latest Venture in Sound Explores Emotive Response and What It Means for Communication
“It’s all about music,” said Gil Weinberg founding director of the College of Design’s Center for Music Technology (GTCMT). Weinberg is also a School of Music professor and School of Interactive Computing adjunct professor.
“Music is about rhythm, pitch, loudness, and tone. These are the same elements used to control vocal prosody, which helps convey emotion, humor, irony, and other subtle, yet crucially meaningful expressions. This project is about using music to allow our robot Shimi to show emotions not only through his voice, but through his body gestures as well.”
Shimi is a personal robot that communicates with humans through music-driven vocal prosody and gestures rather than words.
When Shimi debuted in 2012, it played songs from a user’s library, analyzed the music, and responded with corresponding gestures. Now, with the help of deep learning and with funding from the School of Computational Science and Engineering (CSE), Shimi can learn emotional cues in people’s voices and respond with emotive voice and movement.
The project’s research team comprises Weinberg, Ph.D. student Richard Savery, and master’s student Ryan Rose.
Using deep learning analysis of music and language datasets, the team trained Shimi to communicate emotions using non-linguistic channels. Shimi can also analyze a person’s tone and speech in order to respond in an emotionally appropriate way.
“By modeling humans’ affective communication cues, such as body gestures and vocal prosody, we’ve created a language focused on emotion. With Shimi, we are not projecting words but still allowing for affective communication to occur,” Weinberg said.
Avoiding the “Uncanny Valley”
“Society has seen countless efforts to re-create humanoid robots to interact with humans. Many of these robots fall prey to the same issue as their predecessors: The Uncanny Valley. In the Uncanny Valley, robots simply become too close to human, without being human, which tend to lead to a sense of eeriness and revulsion.
“What then if a robot wasn’t trying to sound exactly like a human? What if we celebrated a robot for what it is, and for the things it can do that humans can’t?” Weinberg said.
This is the logic behind steering clear of identifiable words, and instead equipping Shimi with the ability to respond to humans with non-verbal sounds while still being able to convey a general sense of mood.
“If you are upset, Shimi could project that it is also upset, or maybe decide to encourage you using happy prosody,” Weinberg said.
Creating a Language Built on Deep Learning and Music
To create Shimi’s voice, tone, and improvisational response for this project the team fed a Deep Learning network with:
- 10,000 files from 15 improvisational musicians playing responses to different emotional queues
- 300,000 samples of musical instruments playing different musical notes, to add musical expressivity to the spoken word
- One of the rarest languages in existence – a nearly extinct Australian aboriginal vernacular made up of 28 phonemes
By processing these datasets on NVIDIA’s Jetson Board, an embedded GPU optimized for machine learning, Weinberg and his team have been able to allow Shimi to use his new affective voice and sing as a self-contained robot that does not need network connectivity.
Through the desire to combine music with deep learning, Georgia Tech researchers have coincidentally shown that communication simply needs empathy and a tune to take place.
“What we are most excited about is the ability to synthesize various attributes of music, language, and movement through deep learning, and project music as the core element of a robotic communication to show that our robots can understand and convey human emotion,” Weinberg said.
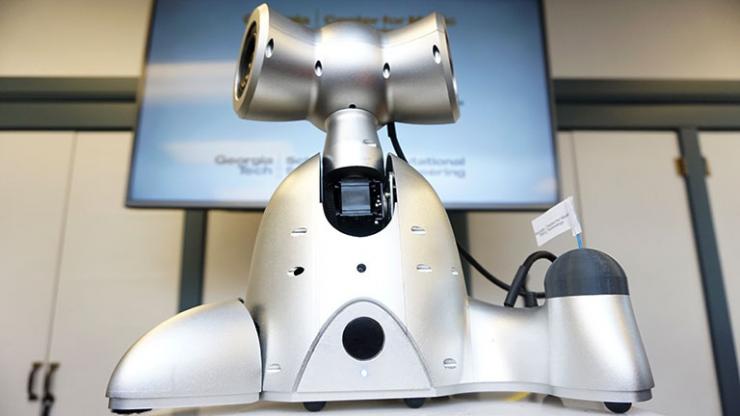
Shimi (2019)
Communications Officer
Kristen Perez



